
Nel suo ultimo rapporto, la società di ricerca indipendente SemiAnalysis punta i riflettori su DeepSeek, un astro nascente nel settore dell’intelligenza artificiale, sfatando alcuni miti sui suoi costi e confrontandoli con quelli della concorrenza.
Una delle voci più diffuse è che la formazione di DeepSeek V3 costi circa 6 milioni di dollari. SemiAnalysis, però, contesta questa cifra, dimostrando come essa trascuri diversi fattori cruciali. In realtà la società cinese avrebbe barato nel dichiarare gli effetti costi di sviluppo, che sarebbero un multiplo molto maggiore rispetto a quanto dichiarato.
Il mito dei 6 milioni di dollari di DeepSeek
La stima di 6 milioni di dollari considera principalmente le spese di pre-formazione della GPU, trascurando i significativi investimenti in ricerca e sviluppo, infrastrutture e altri costi essenziali sostenuti dall’azienda.
Il rapporto sottolinea che la spesa totale in conto capitale (CapEx) dei server di DeepSeek ammonta a ben 1,3 miliardi di dollari.
Gran parte di questo impegno finanziario è diretto al funzionamento e alla manutenzione dei suoi ampi cluster di GPU, la spina dorsale della sua potenza di calcolo.
Secondo quanto riferito, DeepSeek ha accesso a circa 50.000 GPU Hopper, il che ha generato alcune idee sbagliate nel settore.SemiAnalysis chiarisce che ciò non equivale a disporre di 50.000 H100, come alcuni avevano precedentemente dedotto.
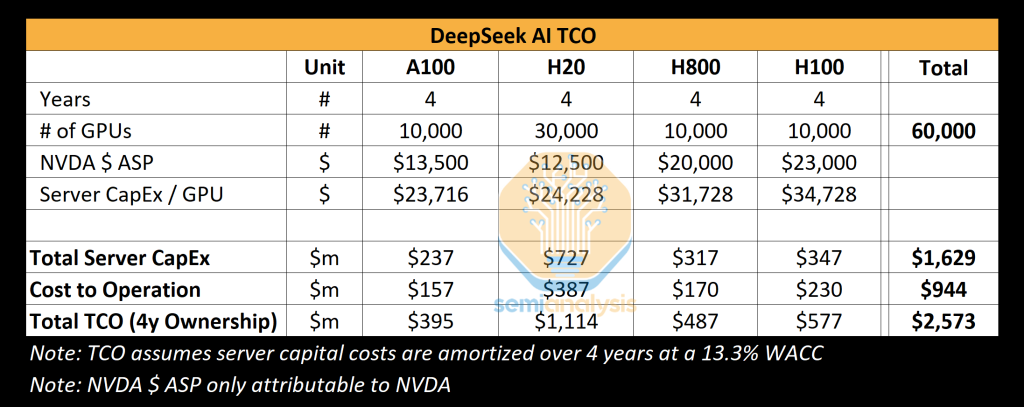
Ipetesi di reale impiego dei GPU nello sviluppo di Deepseek
L’inventario delle GPU comprende invece un mix di modelli, fra cui H800, H100 e H20, specifici per ogni paese, prodotti da NVIDIA in risposta alle restrizioni alle esportazioni degli Stati Uniti.
Questa comprensione sfumata dell’inventario hardware sottolinea le decisioni strategiche di DeepSeek in materia di sourcing ed efficienza operativa.
Un aspetto notevole del rapporto è la riflessione sulla struttura organizzativa di DeepSeek.
A differenza di alcuni grandi laboratori di IA, DeepSeek gestisce i propri data center e impiega un modello semplificato che ne favorisce l’agilità e l’efficienza. Con la crescente competitività del panorama dell’IA, questa capacità di adattarsi rapidamente diventa una risorsa vitale.
Migliori capacità di ragionamento
Dal punto di vista delle prestazioni, l’analisi indica che il modello R1 di DeepSeek dimostra capacità di ragionamento paragonabili a quelle di o1 di OpenAI.
Tuttavia, non si può dire che DeepSeek sia il leader indiscusso in ogni parametro di prestazione.
Sebbene la strategia dei prezzi di DeepSeek abbia raccolto attenzione e riconoscimenti, c’è un’importante avvertenza: Gemini Flash 2.0 di Google, che ha capacità simili, si dimostra ancora più economico quando vi si accede tramite servizi API. Questo pone DeepSeek di fronte a un bivio in cui l’equilibrio tra prestazioni e costi è la chiave del suo successo futuro.
![]()
![]()
La tecnologia Multi-Head Latent Attention (MLA) è un’innovazione innovativa evidenziata nel rapporto.
Questo approccio all’avanguardia riduce in modo significativo i costi di inferenza di un impressionante 93,3% grazie alla riduzione dell’uso del caching dei valori-chiave (KV), rappresentando un importante passo avanti verso soluzioni di IA economicamente vantaggiose.
Gli esperti suggeriscono che le innovazioni emerse da DeepSeek saranno probabilmente adottate rapidamente dai laboratori di IA occidentali, desiderosi di rimanere competitivi. Quindi il vantaggio competetitivo di DeepSeek è destinato a non durare a lungo, in una continua guerra competitiva.
Se da un lato c’è ottimismo sui potenziali miglioramenti e sui guadagni di efficienza, dall’altro SemiAnalysis mette in guardia dalle sfide esterne.
Il rapporto ipotizza che i costi operativi potrebbero quintuplicarsi entro la fine dell’anno, grazie alla capacità di DeepSeek di adattarsi rapidamente alle sue controparti più grandi e burocratiche.

Grazie al nostro canale Telegram potete rimanere aggiornati sulla pubblicazione di nuovi articoli di Scenari Economici.
***** l’articolo pubblicato è ritenuto affidabile e di qualità*****
Visita il sito e gli articoli pubblicati cliccando sul seguente link
